
Fare scraping molto spesso può risultare abbastanza complesso, soprattutto se non si hanno delle basi di programmazione come Python, NodeJS o PHP.
Con Screaming Frog, però, esistono dei piccoli trucchetti che potrebbero aiutarti a cercare un determinato elemento all’interno di una pagina o di tutto il sito web.
Ad esempio, vogliamo sapere quante volte una determinata parola viene ripetuta all’interno di una pagina, quante volte un elemento, un <div> o uno <span> sono presenti all’interno di un contenuto e quale valore hanno.
Apriamo quindi il software Screaming Frog (puoi scaricarlo da qui) e prendiamo il sito web che vogliamo analizzare, in questo caso ho scelto searchenginejournal.com, uno dei migliori siti web che tratta di SEO e di Marketing Online.
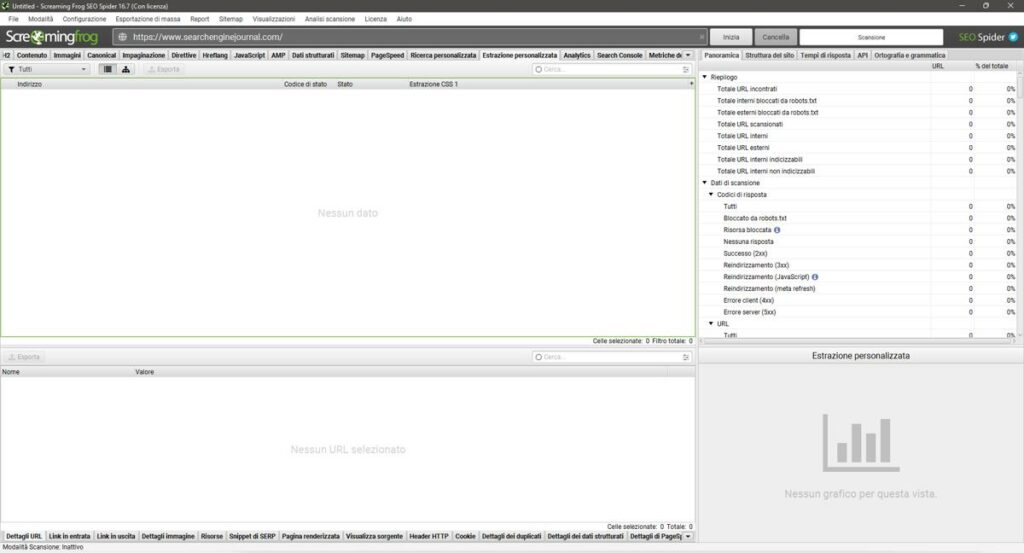
Inseriamo quindi il portale all’interno della barra di ricerca, poi rechiamoci sotto a voce Configurazione > Personalizzata > Estrazione.
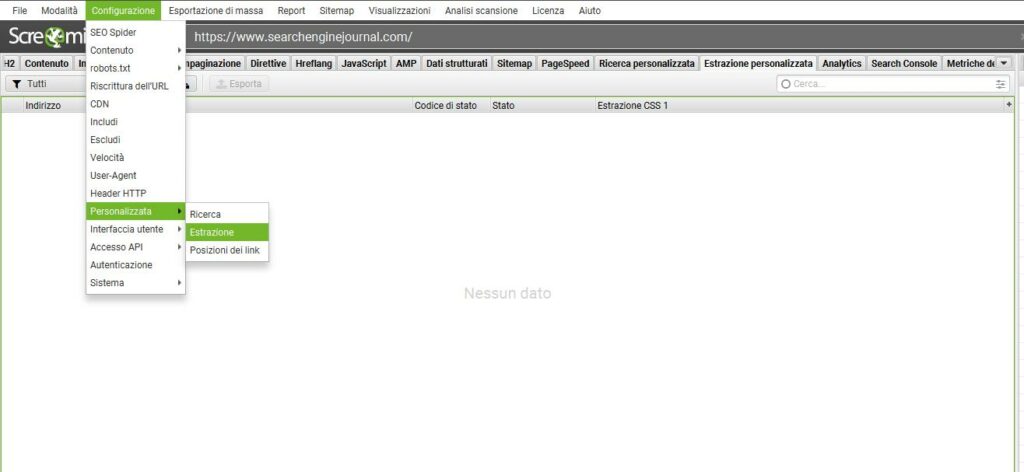
A questo punto, prima di continuare con la configurazione di Sceraming Frog, dobbiamo recarci all’interno del portale, utilizzare il nostro vecchio amico “Ispeziona Elemento” e visualizzare effettivamente la percorso CSS (CSS Path) di nostro interesse.
Supponiamo di voler prendere la data di pubblicazione dell’articolo, quella che è dichiarata dal portale nella pagina:

In questo caso è “1 hour ago“.
Apriamo il nostro ispeziona elemento, io utilizzo per comodità quello di Chrome, ed andiamo a rintracciare l’elemento HTML che corrisponde alla data.
Molto spesso, soprattutto i grandi portali o le realtà che utilizzano dei CMS, sono soliti aggiungere delle classi personalizzate agli elementi più importanti, così da poter dare uno stile CSS particolare ad ognuno di loro.
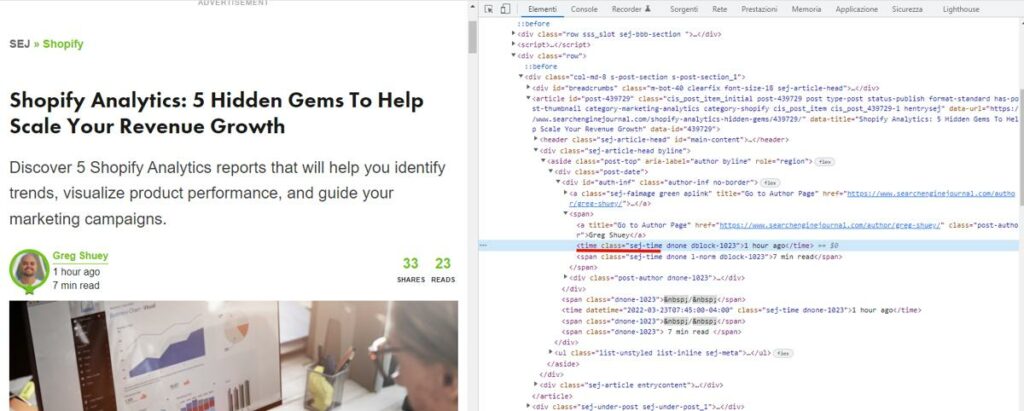
Per il nostro esempio, l’elemento HTML che corrisponde alla data è <time> e la sua classe, assegnata in questo caso solo a lui, è: .sej-time
Il punto, se non lo sapessi, sta ad indicare una classe nel codice CSS.
La nostra path CSS sarà quindi:
time.sej-time
Bene, una volta arrivati a questo punto, possiamo tornare su Screaming Frog ed andare a compilare le ultime parti mancanti per completare il nostro filtro.
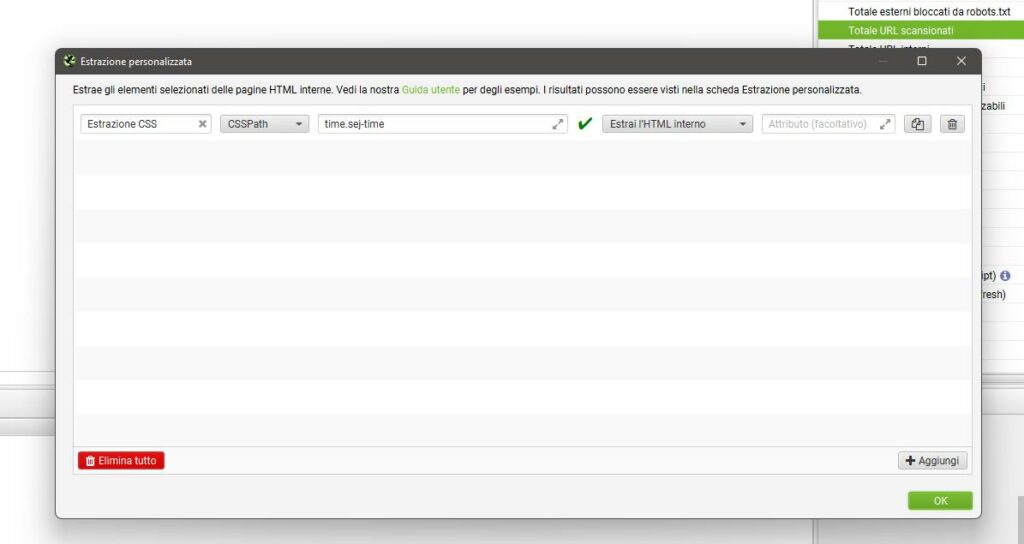
Possiamo quindi rinominare la nostra estrazione con il nome che più preferiamo, selezioniamo “CSSPath” e nel campo di testo andiamo a scrivere la nostra path, quella che abbiamo ricavato poco fa.
Possiamo chiedere a Screaming Frog di estrarre l’HTML completo o solamente il testo contenuto in esso.
A questo punto comparirà la spunta verde ed una volta premuto “OK” siamo pronti per lanciare il crawling.
In automatico, nella TAB chiamata “Estrazioni Personalizzate”, possiamo trovare l’estrazione personalizzata che abbiamo appena creato – se non la trovi prova a scrollare verso destra.
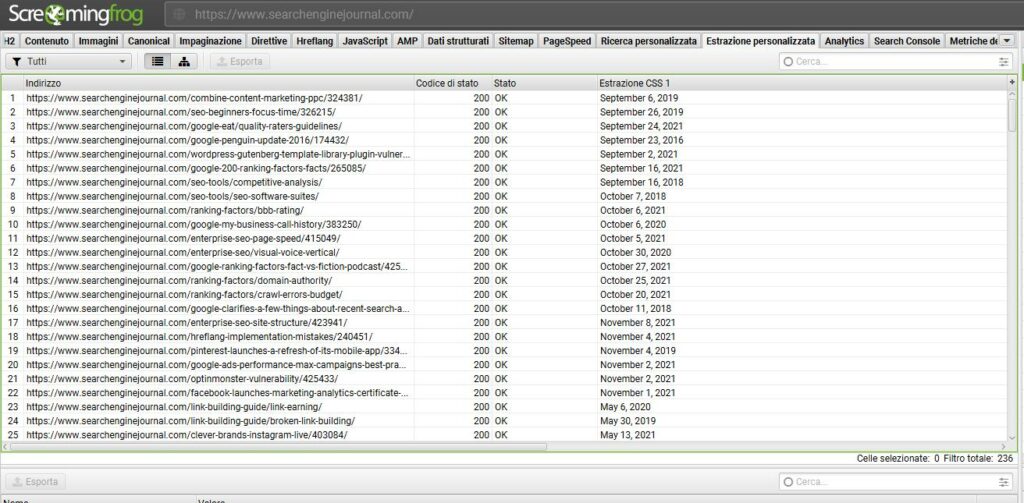
Et voilà. Il gioco è fatto.
Che utilità può avere questa piccola funzionalità di Screaming Frog? Sicuramente, programmando le scansioni, puoi capire dove sta virando la strategia dei tuoi competitors, capire quali sono i contenuti più letti in assoluto e moooolte altre attività da 007.
Fa parte del nostro lavoro.
Ovviamente questo è un esempio molto basico di come poter utilizzare questo strumento per estrarre degli elementi HTML di una pagina, possiamo utilizzare anche delle regole con xPath o RegEX, ma sono discorsi più complessi che meritano una guida apposita.
Per il momento, fai le dovute prove e ricerche basandoti su questa guida.
Buona SEO,
Michele.
Lascia un commento